我读研究生的时候,有一门课就是《神经元网络》,只是那时候还是本世纪初,AI还没有火起来,这门课同学们也不重视,我也学得不咋好,但是讲课的教授有一句话我记得非常清楚,他说,中国人应该在AI上贡献更大,因为中文的语义交织,不是一位数据,而英语之类其他语言其实就是一维的语义。
这当然是教授提升我们自信的一种话术,但是我的自信也真的被提升了。
但是,现在随着我对AI的研究越来越深,我发现——这真的只是提升自信的一种话术/狗头
中文也好,汉字也好,也许从语言学上真的存在多维的信息,但是,对于目前AI主流的大语言模型(LLM),产出依然是一维的token序列。
记住这一点,这很重要!
无论中文,还是英文,或者其他任何语言,对AI来说就是一个token接一个token线性地输出一维序列。
举个例子——
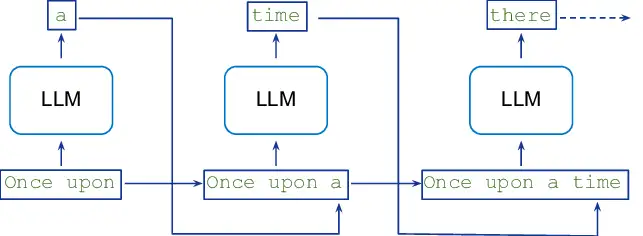
当前文字序列是Once upon,那么LLM可以产出下一个token是a,得到Once upon a。
现在文字序列是Once upon a了,那么LLM又根据这个上下文产出下一个token是time,得到Once upon a time。
现在文字序列是Once upon a time了,那么LLM又根据这个上下文产出下一个token是there,得到Once upon a time there。
一次类推,最后能够也许编出一个故事:Once upon a time, there is a monk ……
你换成中文,也一样——
当前文字序列是『曾几』,那么LLM可以产出下一个token是『何』,得到『曾几何』。
现在文字序列是『曾几何』了,那么LLM又根据这个上下文产出下一个token是『时』,得到『曾几何时』。
现在文字序列是『曾几何时』了,那么LLM又根据这个上下文产出下一个token是『有』,得到『曾几何时有』。
依次类推,最后也编出一个故事:曾几何时,有一个和尚……
当你明白无论什么语言,LLM都只是根据当前token序列预测下一个token序列,就明白用什么语言没什么大差别。
可能你会觉得中文信息量更浓缩,比英文单词信息量更大。
如果只按字符来算,中文的确信息浓度更大,『我爱你』三个字符,英文需要『I love you』八个字母表示,这还单词之间两个空格字符。
但是,LLM看到的不是字符,而是token。
我们来看看token是怎样,可以利用 https://tiktokenizer.vercel.app/ 来解析字符串为token。
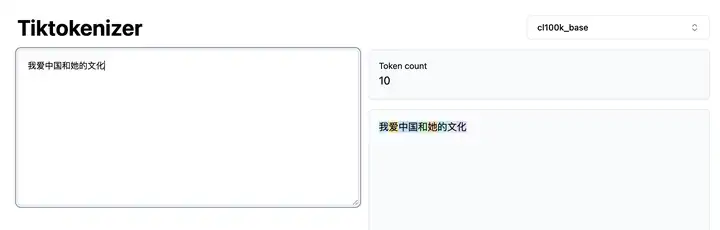
I love China and its culture,被解析成6个token。

我爱中国和她的文化,还需要10个token呢,就是你多大区别。
总之,没有任何证据表示汉字就更适合AI,也许像我当年的教授说的,中文汉字存在多维度语义联系,可以让我们中国人考虑问题更全面,但是,汉字本身,对于就是产生token序列的LLM而言,和英文没有什么本质区别。
所以,不要说什么『汉字会为中国AI插上腾飞的翅膀』。
但是,我们这些说中文的中国人有五千年文化的积淀,经过了百年耻辱的洗礼,走过了几十年的民族崛起,尤其是这几年报复出来的民族自信、制度自信、能力自信,都能让中国AI(或者任何一个其他领域)插上腾飞的翅膀。